Managing Demand Surge During a Viral Campaign
Table of Contents
Introduction
In a fast-paced retail environment, a sudden surge in demand can disrupt even the most carefully planned supply chains. GreenMart Supplies faced such a challenge when a newly launched marketing campaign for their best-selling product, Product P1, went viral overnight. Promising “next-day delivery, always in stock,” the campaign drew unprecedented attention, causing sales to spike by 200% within 24 hours. The unexpected demand put immense pressure on inventory levels, creating the risk of stockouts and unfulfilled orders that could tarnish the company’s reputation. The challenge was clear: GreenMart needed an immediate, data-driven solution to forecast demand, replenish inventory, and ensure seamless order fulfillment during this critical period.
As a Demand Forecaster for GreenMart Supplies,I need to create an accurate and agile forecast specifically tailored to the unprecedented demand surge caused by the viral campaign, so that I can provide actionable insights to the supply chain team for timely inventory replenishment.
Objective
This project delves into how advanced forecasting techniques can fit the historical data and perform an accurate forecasting.
Data Source
The data is from Statso Here is the link There are 5 columns:
- index
- Date (Date)
- Product_ID (String)
- Demand (Integer)
- Inventory (Integer)
in terms of forecasting demand we just need the date as index and the demand column. However for calculating optimized inventory (safety stock calculation etc.), we need to create some assumptions.
Analysis
Let’s start with importing some modules for visualisation and time series forecast
Data Exploring
import pandas as pd # Pandas is a Python library used for working with data sets. It has functions for analyzing, cleaning, exploring, and manipulating data.
import numpy as np # NumPy arrays facilitate advanced mathematical and other types of operations on large numbers of data
import plotly.express as px # Plotly express is a high-level data visualization package that allows you to create interactive plots with very little code
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# plot_acf: Plots lags on the horizontal axis and correlations on the vertical axis
# plot_pacf: Plots lags on the horizontal axis and correlations on the vertical axis. It also allows you to specify the calculation method, such as Yule Walker, Levinson-Durbin recursion, or regression of time series on lags
import matplotlib.pyplot as plt # Matplotlib allows you to generate plots, histograms, bar charts, scatter plots, etc
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error
# Exporing the data
df = pd.read_csv("demand_inventory.csv")
df.info()
df['Date'] = pd.to_datetime(df['Date'],format='%Y/%m/%d')
# we have the demand from 2023-06 to 2023-08 (2 months)

-
Data Cleaning
Only keep the column date and demand to fit in the forecast model
df_demand = df[['Date','Demand']] df_demand = df_demand.set_index('Date') df_demand.info()
-
Data Visualisation
Visualise the data and see if we can identify a pattern
plt.figure(figsize=(20,5)) plt.plot(df_demand)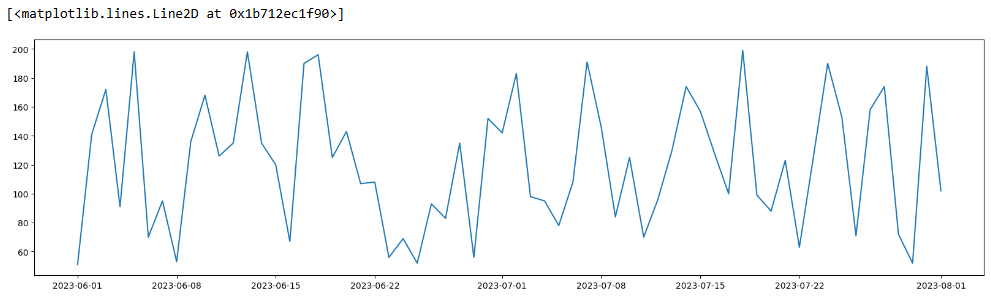
-
Data Validation
Check if the data is suitable for an ARIMA model by determining whether it is stationary or not.
# import the ADF (Augmented Dickey-Fuller) test
# H0: The Time Series is non-stationary
# H1: The Time Series is stationary (which ARIMA models work best with)
# If p value < 0.05 then reject H0
from statsmodels.tsa.stattools import adfuller
# create a function that returns the necessary metrics to test stationarity
def test_stationarity(timeseries):
dftest_initial = adfuller(timeseries)
dfoutput_initial = pd.Series(dftest_initial[0:4],
index=['Statistical Test',
'p-value',
'#Lags used',
'Number of observations'
])
for key, value in dftest_initial[4].items():
dfoutput_initial['Critical value ' + key] = value
print(dfoutput_initial)
print('\n')
test_stationarity(df_demand)
The original timeseries is stationary.
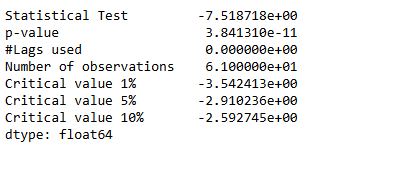
# Validate the above hypothesis
from pmdarima.arima.utils import ndiffs
ndiffs(df.Demand,test="adf")
ARIMA Model
- determine p & q value
p = last lag where the PACF value is out of the significance band
q = last lag where the ACF value is out of the significance band (displayed by the confidence interval)
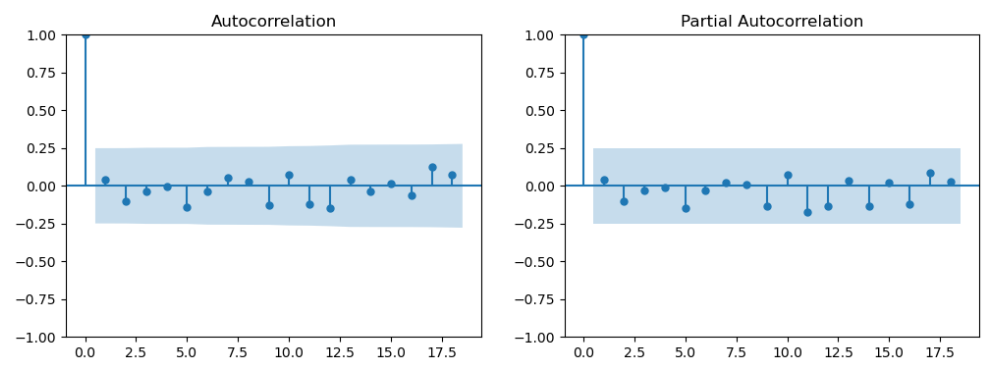
# ref: https://www.linkedin.com/pulse/time-series-episode-1-how-select-correct-sarima-vasilis-kalyvas-jqcjf/ differenced_series = df_demand fig,axes = plt.subplots(1,2,figsize=(12,4)) plot_acf(differenced_series,ax=axes[0]) plot_pacf(differenced_series,ax=axes[1]) plt.show()p and q are in the blue area. Let’s go back the testing and see if we can use differenced df_demand
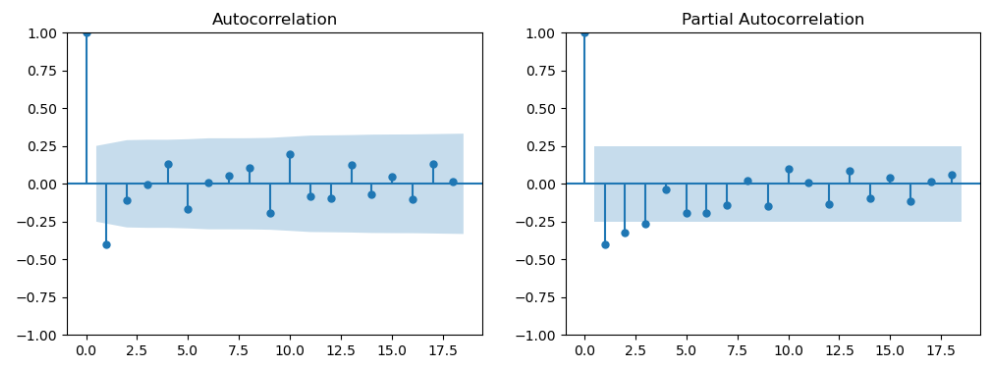
test_stationarity(df_demand.diff().dropna())The first-order differenced (lagged) demand is stationary as well

differenced_series = df_demand.diff().dropna() fig,axes = plt.subplots(1,2,figsize=(12,4)) plot_acf(differenced_series,ax=axes[0]) plot_pacf(differenced_series,ax=axes[1]) plt.show()Now we get q = 1 (PACF plot), d =1 (as we differenced the Time Series), and q = 1 (ACF plot)
- Create training and test data
testing_timeframe = 5
train1 = df_demand.iloc[:-int(len(df_demand)*0.2)]
test1 = df_demand.iloc[-int(len(df_demand)*0.2):]
print('training set (past data): ', len(train1))
print('test set (days to be forecasted ahead): ', len(test1))

- ARIMA result
# import the required modules
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_squared_error
# create and fit the model
model_fit = ARIMA(train1,
order = (1,1,1)
).fit()
print(model_fit.summary())
print('\n')
#####################################################################################
# create forecasts on training set (to evaluate how the model behaves to known-training data)
forecasts_on_train = model_fit.predict()
# create forecasts on test set (to evaluate how the model behaves to unknown-test data)
forecasts_on_test = model_fit.forecast(len(test1))
# calculate the root mean squared error on the test set
RMSE = np.sqrt(mean_squared_error(test1['Demand'], forecasts_on_test))
# print the AIC and RMSE
print('AIC: ' , model_fit.aic)
print('RMSE: ', RMSE)
#####################################################################################
# plot the train and test daat against their corresponding forecasts
# on train data
plt.figure(figsize=(16,4))
plt.plot(train1['Demand'], label="Actual")
plt.plot(forecasts_on_train, label="Predicted")
plt.legend()
# on test data
plt.figure(figsize=(16,4))
plt.plot(test1['Demand'], label="Actual")
plt.plot(forecasts_on_test, label="Predicted")
plt.legend()
when order = (2,1,1), we get the optimised RMSE The second graph shows that we need to add seaonality.
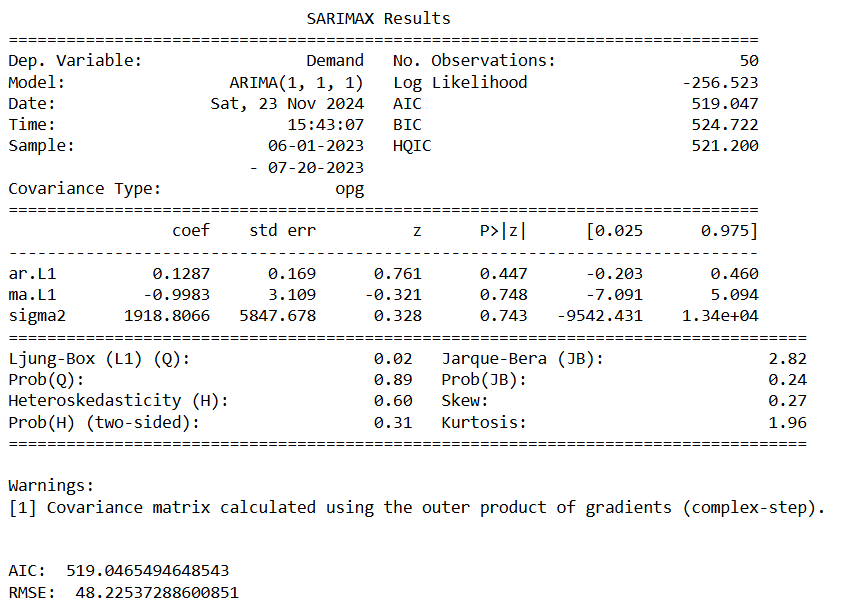
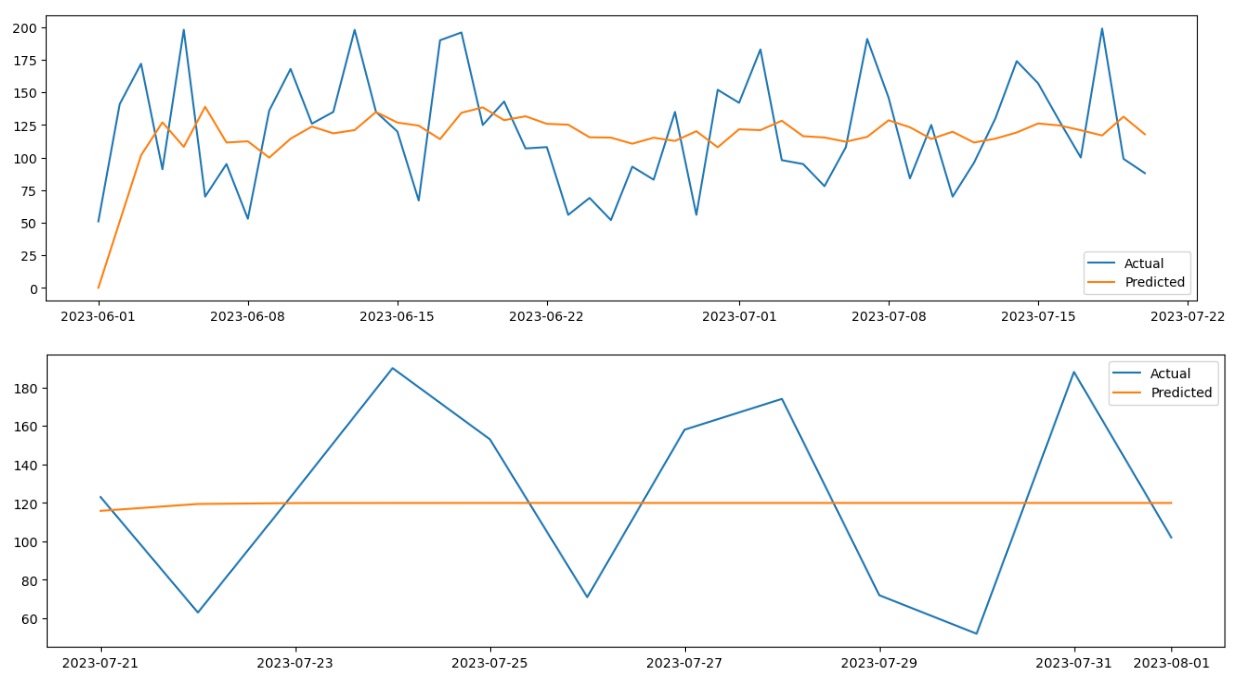
the p-value is greater than 0.05 for AR and MA. Therefore it’s not a good forecasting tool for the dataset. Let’s try SARIMA where we will add seasonaity.
SARIMA Model
# import the required modules
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_squared_error
# D=1 if the series has a stable seasonal pattern over time
# S = ACG lag with the highest value (typically at a high lag), often it is 4 for quarterly data or 12 for monthly data. In this case, S=2
# P>=1 if the ACF is greater than 0 at S=2, else P= 0
# Q>=1 if the ACF is less than 0 at S=2, else Q= 0
# therfore P = 0 and Q = 2
# create and fit the model
model_fit = SARIMAX(train1,order=(1,1,1),seasonal_order=(1,1,2,7)).fit() # S=7 becasue we can see seasonaility every week
print(model_fit.summary())
print('\n')
#####################################################################################
# create forecasts on training set (to evaluate how the model behaves to known-training data)
forecasts_on_train = model_fit.predict()
# create forecasts on test set (to evaluate how the model behaves to unknown-test data)
forecasts_on_test = model_fit.forecast(len(test1))
# calculate the root mean squared error on the test set
RMSE = np.sqrt(mean_squared_error(test1['Demand'], forecasts_on_test))
# print the AIC and RMSE
print('AIC: ' , model_fit.aic)
print('RMSE: ', RMSE)
#####################################################################################
# plot the train and test daat against their corresponding forecasts
# on train data
plt.figure(figsize=(16,4))
plt.plot(train1['Demand'], label="Actual")
plt.plot(forecasts_on_train, label="Predicted")
plt.legend()
# on test data
plt.figure(figsize=(16,4))
plt.plot(test1['Demand'], label="Actual")
plt.plot(forecasts_on_test, label="Predicted")
plt.legend()
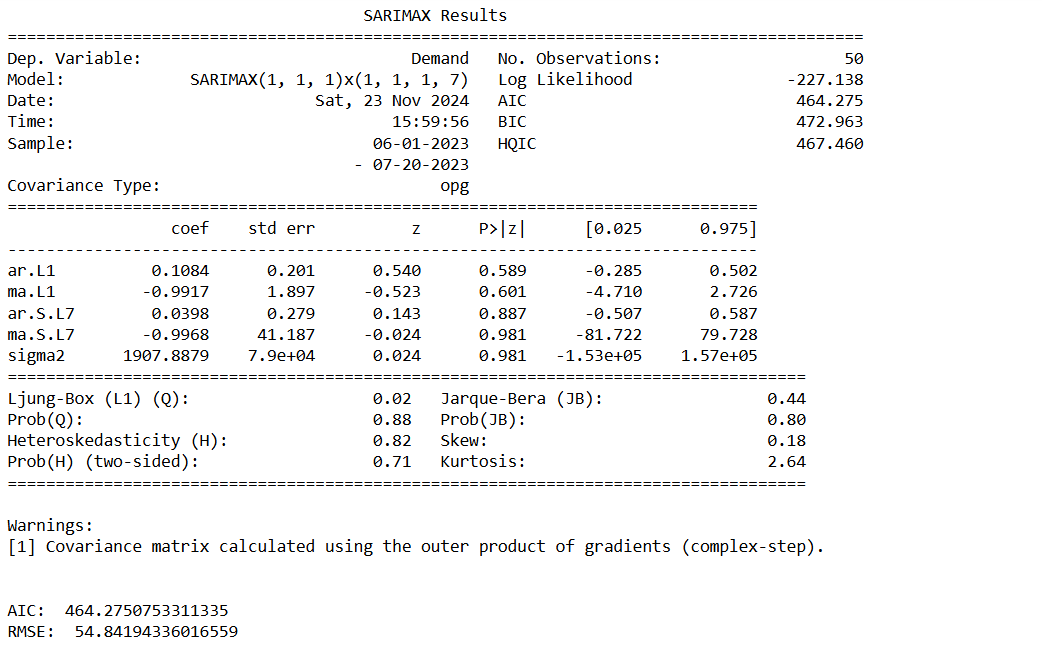
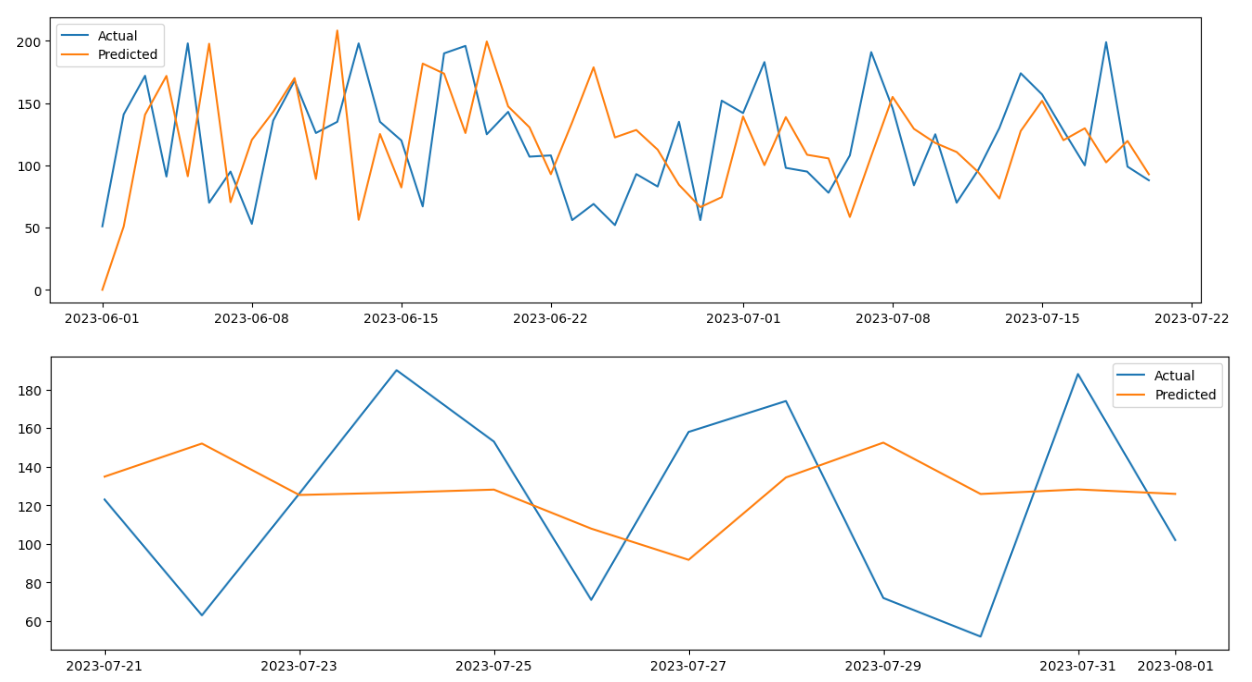
# Create the diagnostics plot to do the final validation.
model_fit.plot_diagnostics(figsize=(14,7))
plt.show()
- Standardized residual: There are no patterns in the residuals.
- Histogram plus kde estimate: The KDE curve should be very similar to the normal distribution.
- Normal Q-Q: Most of the data points should lie on the straight line,
- Correlogram: 95% of correlations for lag greater than one should not be significant.
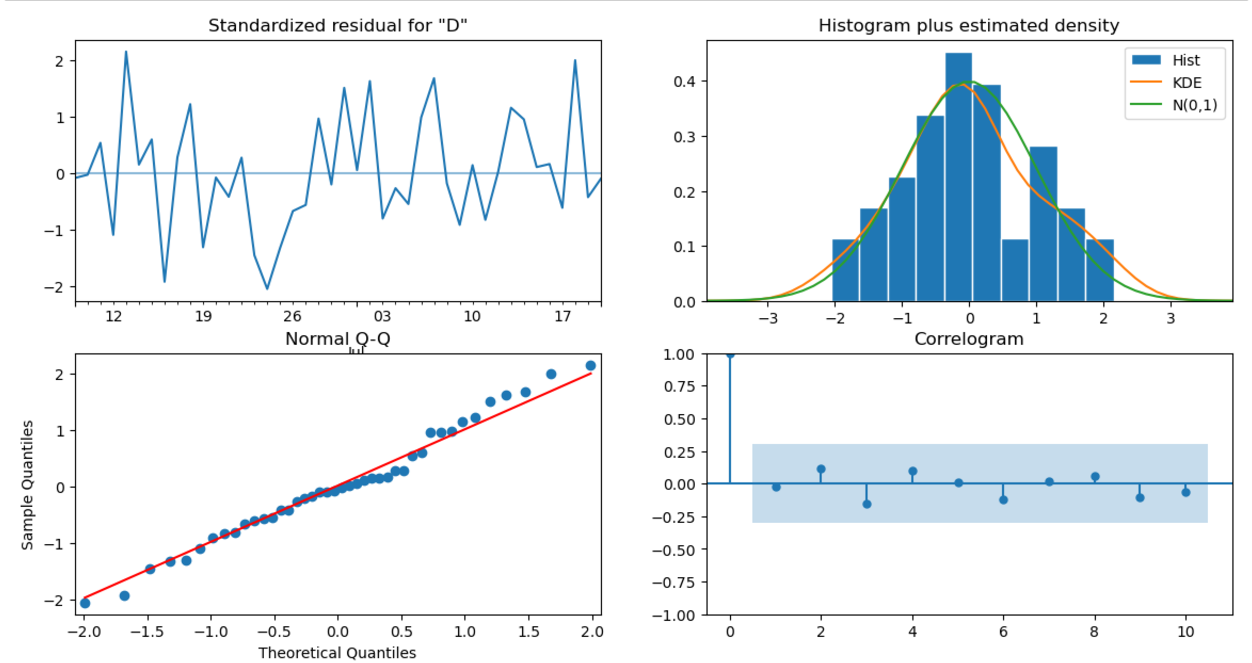
Only Ar.L1 is significant the rest are not, so we might instead using other forecasting tool e.g. Holt-Winters (ETS) model or Prophet.
Holt-Winters (ETS) Model
# Import packages
import plotly.graph_objects as go
import pandas as pd
from statsmodels.tsa.holtwinters import SimpleExpSmoothing, Holt, ExponentialSmoothing
# Read in the data
data = pd.read_csv('demand_inventory.csv')
data['Date'] = pd.to_datetime(data['Date'])
data = data[['Date','Demand']]
# Split train and test
train = data.iloc[:-int(len(data) * 0.2)]
test = data.iloc[-int(len(data) * 0.2):]
def plot_func(forecast1: list[float],
forecast2: list[float],
forecast3: list[float],
title: str) -> None:
"""Function to plot the forecasts."""
fig = go.Figure()
fig.add_trace(go.Scatter(x=train['Date'], y=train['Demand'], name='Train'))
fig.add_trace(go.Scatter(x=test['Date'], y=test['Demand'], name='Train'))
fig.add_trace(go.Scatter(x=test['Date'], y=forecast1, name='Simple'))
fig.add_trace(go.Scatter(x=test['Date'], y=forecast2, name="Holt's Linear"))
fig.add_trace(go.Scatter(x=test['Date'], y=forecast3, name='Holt Winters'))
fig.update_layout(template="simple_white", font=dict(size=18), title_text=title,
width=700, title_x=0.5, height=400, xaxis_title='Date',
yaxis_title='Demand')
return fig.show()
# Fit simple model and get forecasts
model_simple = SimpleExpSmoothing(train['Demand']).fit(optimized=True)
forecasts_simple = model_simple.forecast(len(test))
# Fit Holt's model and get forecasts
model_holt = Holt(train['Demand'], damped_trend=True).fit(optimized=True)
forecasts_holt = model_holt.forecast(len(test))
# Fit Holt Winters model and get forecasts
model_holt_winters = ExponentialSmoothing(train['Demand'], trend='mul',
seasonal='mul', seasonal_periods=7)\
.fit(optimized=True)
forecasts_holt_winters = model_holt_winters.forecast(len(test))
# Plot the forecasts
plot_func(forecasts_simple, forecasts_holt, forecasts_holt_winters, "Holt-Winters Exponential Smoothing")
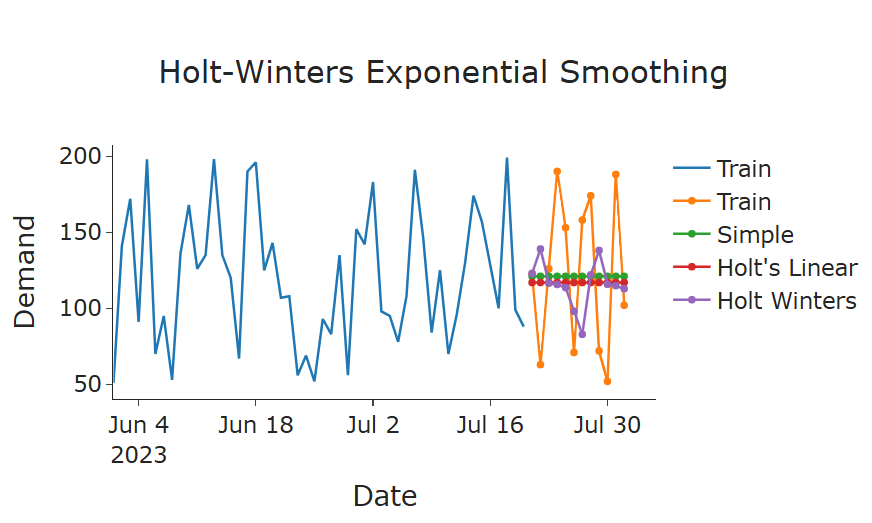
Holt-Winters Exponential Smoothing has the best result over simple and double smoothing
Let’s evaluate the reqult
RMSE = np.sqrt(mean_squared_error(test['Demand'], forecasts_holt_winters))
print(model_holt_winters.summary())
print("RMSE:", RMSE)
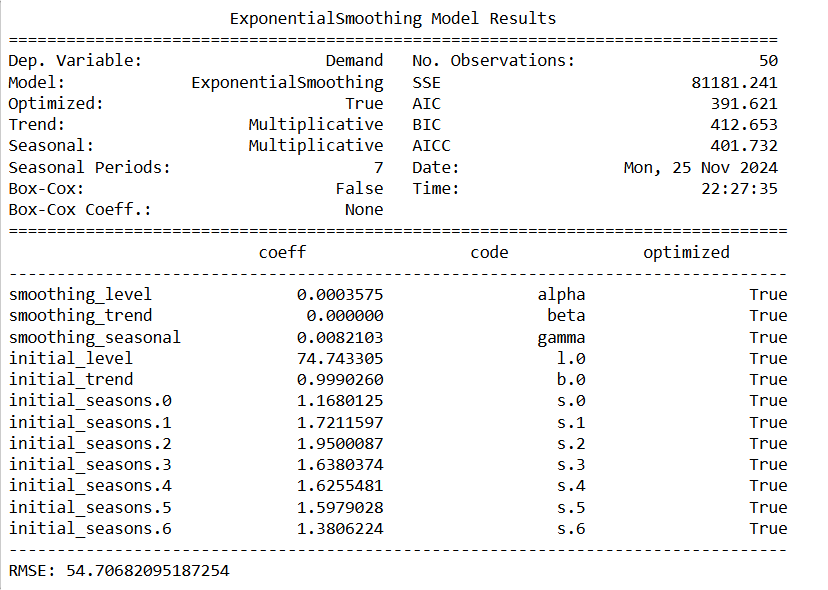
The result shows no trend for the data because beta (trend coef) is 0 and it’s more accurate compared to ARIMA and SARIMA with lower AIC and BIC.
Next, we remove the trend and change the seasonal as additive from the Holt-Winters Model.
# Fit Holt Winters model and get forecasts, using trend as None and seaonal as additive (No multiplicative growth or decay)
model_holt_winters = ExponentialSmoothing(train['Demand'], trend=None,
seasonal='mul', seasonal_periods=7)\
.fit(optimized=True)
forecasts_holt_winters = model_holt_winters.forecast(len(test))
# Plot the forecasts
plot_func(forecasts_simple, forecasts_holt, forecasts_holt_winters, "Holt-Winters Exponential Smoothing")
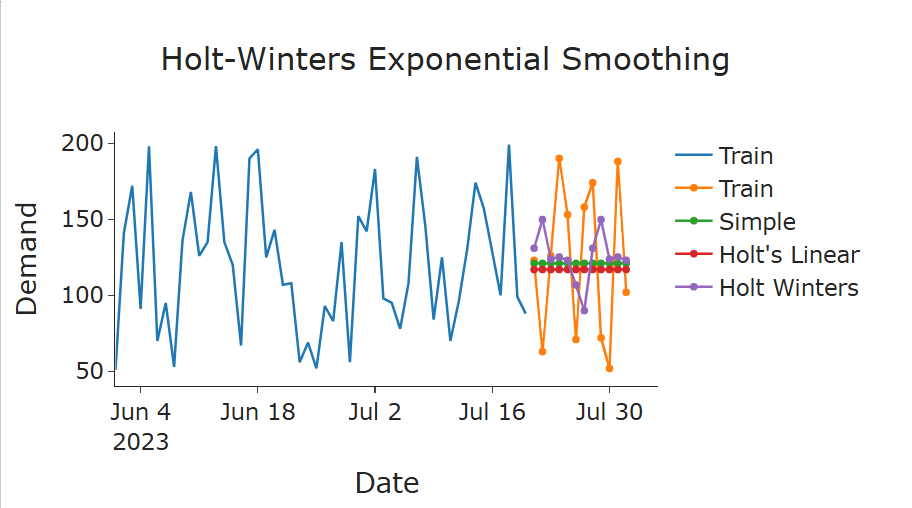
The forecast looks more accurate. To validate, we run the summary and RMSE again.
print(model_holt_winters.summary())
RMSE = np.sqrt(mean_squared_error(test['Demand'], forecasts_holt_winters))
print("RMSE:", RMSE)
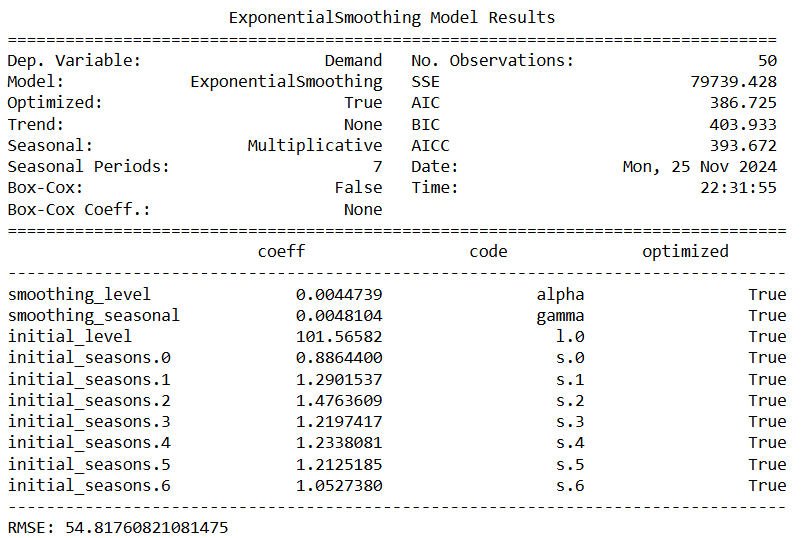
Now we fit the model and forecast for the next 10 days.
# forecast for the next 10 days
model = ExponentialSmoothing(train['Demand'], trend='mul',
seasonal='mul', seasonal_periods=7)\
.fit(optimized=True)
future_steps = 7
predictions = model.predict(len(df_demand), len(df_demand) + future_steps - 1)
predictions = predictions.astype(int)
print(predictions)

# Conclusion In this study, we explored three forecasting models—ARIMA, SARIMA, and Holt-Winters Exponential Smoothing (ETS)—to train and test demand data with a clear seasonal component and no significant trend.
1. ARIMA and SARIMA Models: Despite the data being stationary, which is a prerequisite for ARIMA and SARIMA models, the resulting models produced high p-values for key parameters. This indicated that these models did not capture the underlying patterns in the data effectively, leading to suboptimal forecasts.
2. Holt-Winters Model: The Holt-Winters model was applied to account for the level and seasonal components of the data. The model revealed that the trend coefficient was effectively zero, confirming the absence of a significant trend in the dataset. By excluding the trend component and focusing solely on level and seasonality, the Holt-Winters model produced the most accurate forecasts, as evidenced by the lowest AIC and BIC values compared to ARIMA and SARIMA.
3. Key Findings: The Holt-Winters model outperformed ARIMA and SARIMA due to its ability to directly model the data’s characteristics—constant seasonal variations and no trend. This approach provided a more interpretable and robust solution for forecasting demand. ** 4. Conclusion:** The Holt-Winters model, configured with multiplicative seasonality and no trend, was identified as the best-fit model for this dataset. It effectively captured the underlying patterns, delivering accurate forecasts and outperforming ARIMA-based methods.